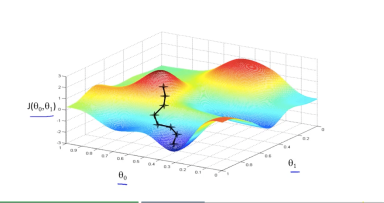
這一系列文主要要介紹一個非常常用到,幾乎是所有做機器學習、深度學習的人都會知道的方法,Stochastic Gradient Descent (SGD) ,大家幾乎把它當基本常識用,但其實他藏有非常神秘、強大的力量。一開始是實驗做多了大家意外的發現,近幾年才開始慢慢有理論研究給予驗證,雖然結果仍然十分有限,但也足夠我們相信這條路應該還有更多有趣的故事可以發掘。但在這之前要先做一點簡單的背景介紹。
Gradient Descent v.s. Stochastic Gradient Descent
Gradient Descent (GD) 和 Stochastic Gradient Descent (SGD) 是兩個十分相像的演算法,但是表現卻天差地遠。Gradient Descent 顧名思義就是利用函數的 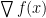
但是大家知道,GD 每當要做一次更新,耗費的計算量很大。因此有另一個改版的更新方式出現,也就是 SGD,他的精神是利用『期望值』的概念,也就是 SGD 只要求走的方向的『期望值』是梯度方向就行了,這樣在夠好的函數上(例如 Convex Function),他仍然有收斂速率的保證(可參考 Shalev-Shwartz 的Ch14)
確切來說, SGD 的做法不需要在每次更新的時候就把所有的 data 看過一次,只要在每個回合﹝iteration﹞隨機從訓練資料 



Non-Convex Function
但是 SGD 的強大並不止於可以做得比 GD 還快,而是我們還發現,他在面對一般的函數也能獲得比 GD 還要好的解。確切來說,一般而言函數是非常複雜的,不會是 convex ,而是 non-convex ;而 neural network 參數量那麼多、又有許多層,整個函數必定是很複雜的,因此此時就很有必要了解為什麼 SGD 幾乎都能夠得到比 GD 好的解。
在這裡簡單介紹 Non-Convex Functions。首先,一般來說解 non-convex function 是一個 NP-hard 問題,例如像是解 4 次多項式函數就已經非常困難。而另外,對於這種 non-convex 函數,我們還必須把『解』定義清楚。也就是說,在 convex function 中,解就只有一個,那就是最低點;但是對 non-convex function 來說就不是這樣了,有所謂的 local minima 和 global minima,例如埔里盆地就是台灣地形的某個 local minima,但他其實不是整個台灣的最低點(global minima),翻過一些山丘後還能繼續往海拔更低處走。整個 non-convex function 很複雜,但是其實在『非水平點』,我們都可以直接沿著 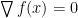
Critical Points
Critical points 其實又可以大致分成三類地形:
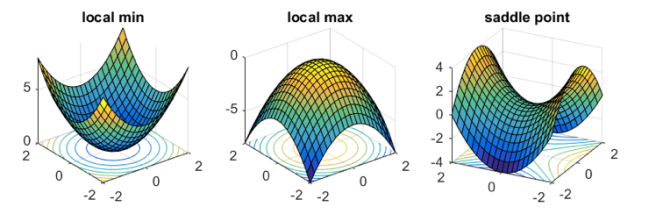
由於這三種地形都是發生在

因此就算 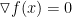
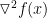
- 如果
, 則這是一個 local minima
- 如果
, 則這是一個 local maxima
- 如果
特徵值(eigenvalues),則這是一個 saddle point
- 而若
前兩點狀況相對的來說單純很多,直接用高中的判別方法:二次微分大於(/小於)零則凹口向上(/下),差別只在因為現在 
Hessian 的特徵值差不多就對應到該處到底是上坡還是下坡,以最終想找到最低點這個目標來說,我們就會希望有多一點負的特徵值,這代表著越多往下的方向,並且希望這些值『很負』,也就代表『很明顯往下』。
Solving non-convex problems
一般來說,就算可以利用 Gradient 或是 Hessian 來幫助得到更好的解,但解 non-convex functions 還是有許多難點,例如:
- 卡在不好的 local minima
- 有非常非常多的 saddle points
- ……
卡在 local minima 十分的麻煩,因爲天曉得在四面的山的背後,有沒有更低的點可以往下走,不像在 saddle points ,至少隱隱約約的還有個缺口可以走。這個問題以後若有機會再詳述。
那至於為什麼會有非常非常多的 saddle points 呢?就算有那麼多的 saddle points 又如何呢?我們不是知道可以往特徵值是負的方向走嗎?『有許多 saddle points』的原因來自於交換對稱(permutation symmetric)。舉個簡單的例子:解 k-clustering 問題。
permutation symmetric:k-means clustering
k-means clustering 的問題是這樣的:假設我是一個老闆,想在一座城市最有效率的蓋 k 間便利商店,請問我該蓋在哪些地方?最有效率意指每間便利商店可以盡量搜集越多顧客、並且彼此不重疊,一個最簡單的想法就是用『距離』分區,而那 k 間便利商店就蓋在那 k 區的中心位置。
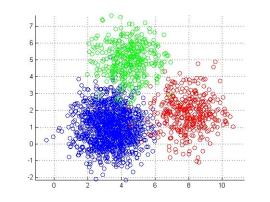
我們用 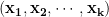

上述原因會使得整個 non-convex function 可能有 exponential 多個 saddle points,這讓我們不清楚我們究竟會在 saddle points 迂迴多少次,而最終能不能(快速)收斂到某個 minima。稍微還算幸運的是,對於許多機器學習會面臨到的問題,『所有的 local minima 都是 global minima』(像是 tensor decomposition, dictionary learning, phase retrieval, matrix sensing, matrix completion, 
接下來的文章中,我們會說明 SGD 的確可以有效逃脫 saddle points ,並且證明他的收斂速度(in iterations)。
[Reference]
- Escaping Saddles with Stochastic Gradients, 2018 ICML
- How to Escape Saddle Points Efficiently, 2017 ICML
- Escaping From Saddle Points – Online Stochastic Gradient for Tensor Decomposition
- Efficient approaches for escaping higher order saddle points in non-convex optimization
- Gradient Descent Can Take exponential time to escape saddle points, 2017 NIPS
