Follow the Regularized Leader (FTRL) 是解 Online Convex Optimization 問題非常常用的方法。以下將簡單介紹 Online Convex Optimization (OCO),並從 Follow the Leader 的角度解釋為什麼需要 Regularizer。
Online Convex Optimization (OCO)
在《機器學習問題–Convex Problems(1)》中有稍微介紹過什麼是 convex problem,也就是這個問題的 prediction set 是一個 convex set ,且 loss functions 是 convex function。那篇文章中說我們會碰到的很多問題都是 convex problem,而且幾乎可以說,現在大家會解的問題也幾乎只有 convex function。讀者可能會質疑:「但是曾經看到一些論文有關 non-convex function 啊?」不過事實是,許多解 non-convex 的方法也是奠基於對 convex problem 的分析,因此最重要的還是 convex function。
而在 online learning 的世界也是。很多時候遇到的問題其實都可以是一個標準 Online Convex Optimization 的形式樣子。

顧名思義,在 OCO 中 
![t\in [T]](https://s0.wp.com/latex.php?latex=t%5Cin+%5BT%5D&bg=ffffff&fg=000000&s=0&c=20201002)








寫 



而 (1) 式的 
Follow the Leader (FTL)
做 online convex optimization 問題,關鍵都在怎麼在每一步做出好的預測,使得每一步的 regret 都不會太大。因為在時間 
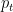

也就是看看那個 
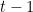
Example( by reference [1])
令 ![S=[-1,1]\subset \mathbb{R}](https://s0.wp.com/latex.php?latex=S%3D%5B-1%2C1%5D%5Csubset+%5Cmathbb%7BR%7D&bg=ffffff&fg=000000&s=0&c=20201002)


很明顯的,如果跑 FTL ,那麼當時間是偶數時, 



由這個例子知道,單純用 FTL 是不可行的,會被 adversary 騙,傻傻的在 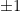
Follow the Regularized Leader (FTRL)
FTRL 其實有很多種解釋方式,以下介紹的這一種應該是需要最少背景知識的,雖然不是很精確。1. 2. 3. 的標號表示這個方法直覺上蠻合理的一些關鍵。
1. 希望可以偷看下個時間的 loss function
前面提到,在時間 
Lemma: 令 


Proof: 用數學歸納法
- 當
時,根據定義可以知道是對的。
- 假設到
時都對,那麼

右式對所有 

最左式是說,當時間 

而這個不等式既然對於最好的後見之明是對的,那麼當然對於所有 
這個證明告訴我們,每一步都都偷看 



(3)、(4) 要求的是 argmin 要很接近,這點蠻比較不 trivial 的,因為就算兩式右邊的函數值差不多,
 ,那麼無論比它彎曲,還是比它平滑,要達到同樣 y 值對應到的 x 不一樣。
,那麼無論比它彎曲,還是比它平滑,要達到同樣 y 值對應到的 x 不一樣。如果 
所以到目前為止,我只知道要選一個 convex function 
2. FTRL 的 update 要夠平滑
前面也提到一個問題,如果從 



給了一堆不嚴謹的解釋後,筆者只是想引出 FTRL 演算法一個可能的解釋方向。而它的演算法:
其中
Analysis of FTRL
有了以上的材料,再加上 convex function 的一些性質,就很容易可以寫下 FTRL 的 regret bound。也就是:





說明:
- (5) 式來自於上面所說:跑 FTL 演算法時當時間
從 (3) 式可以看出,
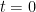



左右整理一下,再兩邊同時加上 FTRL 的 total loss 
- (6) 式從 convex function 的定義得到。

且事實上 

其中 
- (7) 式來自於Online Linear Optimization with
。
因為

所以很剛好的

因此,
- 最後,要使得這個 regret bound 是 finite,除了
也都要是 bounded,因此假設 loss function
-Lipschitz。
這個分析幾乎是將整個 FTRL 的分析模組化了,無論如何,任何 OCO 問題都可以藉由 sub-gradient 簡化成 OLO 問題,而配上不同的 Regularizer 或是不用 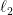
Reference
- Online Learning and Online Convex Optimization, by Shai Shalev-Shwartz
