這份 note 是根據『 Sketching as a Tool for Numerical Linear Algebra — David P. Woodruff 』的講義,以及我們在 2018, fall 的讀書會內容做的簡短整理。
文中的定義都會根據我們在白板上的討論另外改寫,所以不一定會長得跟書本裡一模一樣,不過概念是一致的。
Chapter 2
Section 2.1
Definition 2.1 : A metric 




作者書中的 
![a\in \left[(1-\epsilon)b,(1+\epsilon)b\right]](https://s0.wp.com/latex.php?latex=a%5Cin+%5Cleft%5B%281-%5Cepsilon%29b%2C%281%2B%5Cepsilon%29b%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)

這個定義容許的
另外,我們可能會希望這個 embedding 可以是事先被選好的。也就是說,希望有一個 universal embedding 他可以對所有的 matrix
Definition 2.2 : Suppose 



![\Pr_{S\sim \Pi}\left[ S \mbox{ is a }(1\pm \epsilon) \ell_2-\mbox{subspace embedding for }A\right]\geq 1-\delta](https://s0.wp.com/latex.php?latex=%5CPr_%7BS%5Csim+%5CPi%7D%5Cleft%5B+S+%5Cmbox%7B+is+a+%7D%281%5Cpm+%5Cepsilon%29+%5Cell_2-%5Cmbox%7Bsubspace+embedding+for+%7DA%5Cright%5D%5Cgeq+1-%5Cdelta+%C2%A0&bg=ffffff&fg=000000&s=0&c=20201002)
又或者寫開的話,
![\Pr_{S\sim \Pi}\left[\forall x\in \mathbb{R}^d, \|SAx\|_2^2=(1\pm \epsilon)\|Ax\|_2^2\right]\geq 1-\delta](https://s0.wp.com/latex.php?latex=%5CPr_%7BS%5Csim+%5CPi%7D%5Cleft%5B%5Cforall+x%5Cin+%5Cmathbb%7BR%7D%5Ed%2C+%5C%7CSAx%5C%7C_2%5E2%3D%281%5Cpm+%5Cepsilon%29%5C%7CAx%5C%7C_2%5E2%5Cright%5D%5Cgeq+1-%5Cdelta+%C2%A0&bg=ffffff&fg=000000&s=0&c=20201002)
這是一個蠻強的定義,好用卻不一定好得到,為什麼?因為這個 embedding 的選法跟
在找到一個夠 sparse、或是夠好算的
FJLT approach
FJLT approach 從字面上看起來,蠻顯然的就是希望利用 Johnson Lindenstrauss Lemma 提供的 random projection 方法來提供一種 embedding。接下來要定義所謂的 JLT matrix。
Definition 2.3.0 : A subset 


也就是該集合只有
Definition 2.3 : A random matrix 

where
定義 2.3 是用來描述另一種 
首先關於第一點,如果將所有 

如果現在改要求 2-norm 保值,也就是要求


那麼

也就是說,在這狀況下,2-norm 保值就會 imply inner product 保值。
至於那個 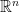


因此這裡我們發現,定義 2.3 跟定義 2.2 的強度落差蠻大的,因為定義 2.2 的那個 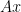
Theorem 2.1: Let 



從這個定理我們驚訝的知道,原來就一個那麼單純、容易建構的
Theorem 2.3 : Let 
(proof idea of Theorem 2.3):
證明這個定理需要花點工夫,不過雖然這個定理看起來很長,很多東西都是重複的,像是最前面一大段描述那個
如果 random matrix


![\Pr_{S}\left[\forall v,v'\in V\quad |\langle Sv,Sv'\rangle-\langle v,v'\rangle|\leq \epsilon\|v\|_2\|v'\|_2\right]\geq 1-\delta](https://s0.wp.com/latex.php?latex=%5CPr_%7BS%7D%5Cleft%5B%5Cforall+v%2Cv%27%5Cin+V%5Cquad+%7C%5Clangle+Sv%2CSv%27%5Crangle-%5Clangle+v%2Cv%27%5Crangle%7C%5Cleq+%5Cepsilon%5C%7Cv%5C%7C_2%5C%7Cv%27%5C%7C_2%5Cright%5D%5Cgeq+1-%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)

![\Pr_S\left[\forall x\in \mathbb{R}^d, \quad \|SAx\|_2^2=(1\pm \epsilon)\|Ax\|_2^2\right]\geq 1-\delta](https://s0.wp.com/latex.php?latex=%5CPr_S%5Cleft%5B%5Cforall+x%5Cin+%5Cmathbb%7BR%7D%5Ed%2C+%5Cquad+%5C%7CSAx%5C%7C_2%5E2%3D%281%5Cpm+%5Cepsilon%29%5C%7CAx%5C%7C_2%5E2%5Cright%5D%5Cgeq+1-%5Cdelta+&bg=ffffff&fg=000000&s=0&c=20201002)
然後就證完了!很顯然的,要完成上述證明有一些事情必須解決:
- 證明定理 2.1(by JL Lemma)
- 證明那個 “hope",也就是證明:如果
,那麼
,其中
。
- 要滿足證明最剛開始的『如果』。那個『如果』一旦不成立,那後面的東西就完蛋了。因此得決定
(proof of Thm 2.1)
這個證明比較容易理解,因此寫得比較簡短。證明可以直接從如果 

也就是對任何 
![\Pr_S \left(\forall v,v'\in [f],\quad |\langle Sv,Sv' \rangle-\langle v,v' \rangle|=\pm \epsilon \|v\|_2\|v'\|_2 \right)\leq 1-f^2\delta](https://s0.wp.com/latex.php?latex=%5CPr_S+%5Cleft%28%5Cforall+v%2Cv%27%5Cin+%5Bf%5D%2C%5Cquad+%7C%5Clangle+Sv%2CSv%27+%5Crangle-%5Clangle+v%2Cv%27+%5Crangle%7C%3D%5Cpm+%5Cepsilon+%5C%7Cv%5C%7C_2%5C%7Cv%27%5C%7C_2+%5Cright%29%5Cleq+1-f%5E2%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)
也就是降維後,有很高的機率,這 

除了定理 2.1 以外,要完成其他兩件事,看起來都跟那個
很明顯的," hope " 中的落差是 




接著要說明 
(proof of hope )
首先,每個 








於是我們證明了對於每個
第二件事是決定 

(show that 
這其實就是一個 “packing and covering" 問題。記得的人就不用繼續看了。關鍵就是 

因此只要能給

這個『至少』問題不好解,因為只要比 optimal 大的答案都是對的,所以我當然可以塞越多越好。不過在原問題中,我希望
現在我可以改用藍球問題來解黃球問題,也就是利用 (b) 式,並給藍球的 optimal 一個上界就搞定了。至於為什麼 (b) 式是呈現這個關係,若要認真寫證明其實也不難,可以參考『Lecture』。 不過偷懶一點的話,其實光是看上圖就知道了。上圖的黃球和藍球的紅色球心重合,而這組紅色球心,正好都是黃球問題和藍球問題的合法解,此時黃球和藍球一樣多。而黃球問題的 optimal 只會更少(拿掉幾個還是可以覆蓋整張圖),而藍球問題的 optimal 只會更多(可以再多塞幾個藍球),因此顯然 (b) 式是對的。
最後最後,藍球問題的上界怎麼求呢?可以考慮藍球在單位球之內的狀況,顯然個數就是球的體積比。不過還有一件小事就是,事實上我們允許球心在邊界上,所以藍色球覆蓋的區域會稍微更大一點,整個大球半徑會是 

至此我們證完定理 2.3 以及它所需要的所有事情了!
