這篇文章其實是延續《GAN 系列文 (4)》中提到的一項理論猜測:對於只有 n 個參數的 discriminator , generator 只要學會由 
p.s. 文章中會不斷出現『support』這個字,是表示『由 X 個 sample 構成的 distribution』的意思。
Generator 的 Support 量的實驗結果
對於真實的 
- CelebA 上訓練出來的 support 量

- CIFAR-10上訓練出來的 support 量

為什麼要特意用「平方」表示繼續看下去就知道了,不過總而言之,沒錯,support 量真的很少。意思是在 CIFAR-10上訓練,然後想要學會怎麼產出『馬』的圖片,你只要產生了像是 
生日悖論
不知道有沒有人發現我上一節的最後一行給的這個提示 (?) ,沒錯,檢測 support 量的方法就是利用生日悖論,儘管我不喜歡稱它為「悖論」,因為它其實只是不太符合直覺而已。而既然用這個方法,就簡單複習一下。
《生日悖論》說的是,一年有 365 天,但一個房間裡只要有超過 23 個人,那麼至少有 2 個人生日是同一天的機率就大於 50% 。證明其實非常簡單,可以看 [參考資料 3] 的網站。總之,在這裡『support 量』就是 365,而 23 就是會發生『碰撞』 ( Collision ) 的大小。如果很大略的看,這兩個大概是平方關係,這也是為什麼上面的圖表會用平方表示。
生日問題是已經知道 support 大小,不知道 collision 的大小;我們的問題是,我們可以做實驗知道 collision 的大小,希望可以藉此推算 support的大小。
這裡唯一需要注意的一點是,在生日問題這種離散的問題,很容易就能知道什麼時候發生『碰撞』,那就是兩人生日同一天的時候。但是對於 GAN 產生的圖片,其實也不太容易有兩張圖完全一樣的情況,況且就算只差 1 個像素我們也看不出來,因此只能尋找『相似』的圖片。他們的實驗流程如下:
- 從
中〈generator 產生圖片的分佈〉抽出 N 張圖片。
- 先讓電腦很概括的選擇 20 組它覺得相似的圖〈可以直接算 pixel 間的距離,反正只是很粗略的過濾〉
- 人為檢查這 20 組是不是真的有『相似的』圖片。有的話打個勾、沒有打個叉〈這我自己加的,注意每 N 張圖片只會有一個記號,而不是把 20 組都各別做記號〉
- 重複 1~3
最後看打勾的個數有沒有佔所有記號的 50% 以上,有的話那 N 就是發生 collision 的大小了,並且 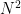
diversity v.s. discriminator size
還有另一個實驗。在《GAN 系列文 (4)》中,我們知道理論上如果 discriminator size 只有 n,則 support 只要 


Generator 會不會硬背 m 張圖?
作者強調,diversity 不夠,或是說 support 不夠多的問題,跟傳統上我們害怕機器會直接把圖片硬背下來其實不一樣,下面用一張圖說明就算 generator 的 support 很低,也就是很容易產生類似的圖,但它也沒有慘烈到直接把圖背下來,還是有一些差異的。

Encoder-Decoder GAN
另外,觀察表一、還有圖二作者自己改良普通 GAN 後的 MIX+GAN support 量還是不幸的沒有增加,但是最右邊那個模型,ALI,不知道有沒有人發現,很奇怪的,它的 Support 量特別多。這個模型和另一個等價的模型是 biGAN,是所謂的 Encoder-Decoder GAN ,這引發了作者的好奇,他們想:說不定這個結果告訴我們, Encoder-Decoder GAN 這種模型其實是更好的改版方向。
不過在今天11 月的時候,作者又發了今年關於這個主題的第三篇論文,說明 Encoder-Decoder GAN 其實也會碰到跟其他模型差不多的問題,證明的方法跟《GAN 系列文 (4)》用的差不多,主要的差異在:
- GAN 只有 generator 和 discriminator
- generator 吃進一個亂數
,並產生
- discriminator 試圖判斷一個圖片 x 究竟是從 generator 來的還是從真正的
- generator 吃進一個亂數
- encoder-decoder GAN 有 generator、encoder 和 discriminator
- generator 吃進一個亂數
。generator 的目標是希望這個
。
- encoder 吃進一張真正的圖
,並輸出
。encoder 的目標是希望可以將
空間,看看它對應回該空間是哪個點。輸入輸出可以寫成一對
。
- generator 和 encoder 試圖讓
- discriminator 試圖區分
- generator 吃進一個亂數

非常非常簡略的講,generator 跟 encoder 其實是合作關係,他們要一起騙過 discriminator 。Encoder 的角色其實是用來幫助 generator 學到更多有意義的特徵,或許是這個理由讓 encoder-decoder GAN 的 diversity 增加了。作者證明的方法是,因為 discriminator 目標是要試圖區分

GAN系列文(5)–GAN 真的有學到真實分佈嗎? 有 “ 1 則迴響 ”