這篇文章基本上延續了《GAN系列文(2)–Generative Adversarial Nets》對於 GAN 這個模型的研究。先稍微對 GAN 的幾個重要結論做個小複習:
GAN 的目標函數是:
![\min_G\max_D \mathbb{E}_{x\sim P_{data}}[log(D(x))]+\mathbb{E}_{x\sim P_G}[log(1-D(x))]](https://s0.wp.com/latex.php?latex=%5Cmin_G%5Cmax_D+%5Cmathbb%7BE%7D_%7Bx%5Csim+P_%7Bdata%7D%7D%5Blog%28D%28x%29%29%5D%2B%5Cmathbb%7BE%7D_%7Bx%5Csim+P_G%7D%5Blog%281-D%28x%29%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
而最佳的 discriminator 是:

當手上握有那麼好的 discriminator 時,Generator 的目標就是去最小化 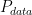


本篇的主軸會放在回答那一篇文章最後提問的部分問題:
- 當訓練資料不夠多時、或是當 discriminator 的類神經網路不夠強大時,整個訓練過程還會有一個平衡點 ( Equilibrium ) 嗎?(類神經網路其實也是有很多的參數去調控的,當參數量不夠多時,網路的可調性也受限,此時就不一定能有
那麼好的 discriminator 了。)
- 若真有一個平衡點,那一定會是 Generator 贏過 Discriminator 嗎?
- Generator 贏過 Discriminator 時,就表示
嗎?
Generalization
在上述對 GAN 的分析中,有兩項後來受到質疑的關鍵假設:
- 有足夠多的訓練資料可以去逼近、或是估計目標函數 [ 式 (1) ]
- 假設實際上 Discriminator 的可調參數量有 n 個。則這 n 個參數所構成的 Discriminator 的集合,真的大到有辦法挑到
首先,不知道讀者還記不記得 《機器學習可行嗎 (3)– uniform convergence》的重點?總之就是我們 i.i.d. 的取 m 筆訓練資料,然後希望只要 m 夠大,對這 m 筆資料的估計就已足夠代表真實情況。也就是
![Pr[|\frac{1}{m}\sum\limits_{i=1}^m l(x_i) - \mathbb{E}_{x\sim D} l(x)|\leq \epsilon]\geq 1-\delta](https://s0.wp.com/latex.php?latex=Pr%5B%7C%5Cfrac%7B1%7D%7Bm%7D%5Csum%5Climits_%7Bi%3D1%7D%5Em+l%28x_i%29+-+%5Cmathbb%7BE%7D_%7Bx%5Csim+D%7D+l%28x%29%7C%5Cleq+%5Cepsilon%5D%5Cgeq+1-%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)
這就是 generalization 。從估計手上握有的情況,推展到真實情況。而 GAN 的目標也是希望能夠使得 
定義: (generalize)
給定 m 個從 

![Pr[|d(P_{real},P_{G})- d(\hat{P}_{real},\hat{P}_{G})|\leq \epsilon]\geq 1-\delta](https://s0.wp.com/latex.php?latex=Pr%5B%7Cd%28P_%7Breal%7D%2CP_%7BG%7D%29-+d%28%5Chat%7BP%7D_%7Breal%7D%2C%5Chat%7BP%7D_%7BG%7D%29%7C%5Cleq+%5Cepsilon%5D%5Cgeq+1-%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)
這裡 

在這個定義中,


這件事情為什麼重要,因為在這篇論文發表以前,所有跟 GAN 有關的模型討論的距離函數,不外乎就是 JS divergence、KL divergence,或是 Wasserstein distance。(關於這些距離,可以參考《GAN 系列文 (1) 》)但非常不幸的,這些距離在
例子:現在有 






¤

為了克服這個麻煩,因此又有了另一個距離的定義產生:
定義:(Neural net distance)
對於兩個 distribution 
![d_F(\mu,\nu)=sup_{D\in F}\mathbb{E}_{x\sim \mu}[D(x)]-\mathbb{E}_{x\sim \nu}[D(x)]](https://s0.wp.com/latex.php?latex=d_F%28%5Cmu%2C%5Cnu%29%3Dsup_%7BD%5Cin+F%7D%5Cmathbb%7BE%7D_%7Bx%5Csim+%5Cmu%7D%5BD%28x%29%5D-%5Cmathbb%7BE%7D_%7Bx%5Csim+%5Cnu%7D%5BD%28x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
而 


Neural net distance 可以被 generalize 直觀上的理由可以想成:
整個 discriminator 的集合雖然很大,但其實看其中有限多個 discriminator 就已經足以代表全部 discriminator 的行為,但是很不幸的,只要 
更詳細地說:
- 如果
跟
對於同一筆資料
給出的結果其實幾乎一樣,那就可以將它們劃分為『同一種 discriminator』(L-lipschitz w.r.t.
- 因為這些 discriminator 只有 n 個可調參數,因此如果有兩個分佈:
〉,有很高的機率,所有這些有限個 discriminator 都沒有辦法分辨
Generalization v.s. Diversity
從上面的討論可以得到一些重要的觀察,這大概也是這一節最重要的事情,如果前面都看不懂只要記得這些就好 (?):
- 我們說 generator 會 『贏』 discriminator ,指的是,discriminator 對任何一筆資料的預測都跟用 1/2 的機率亂猜沒什麼兩樣。
和要求的精確度
有關。
- 取更多的 sample 其實對 training 沒有太大的幫助〈這是很違反傳統機器學習的直覺的!〉,因為無論如何 discriminator 都沒有辦法分辨。
- 既然 discriminator 的能力那麼受限於 n ,連 generator 到底只學到了
,而不是理想中
。generator 可能根本還學不到真正的分佈,也就是 generator 產生的圖的 diversity 可能不夠!
針對第 4 點,因為這純粹是理論上說它『可能發生』,但不一定真的就發生了,因此幾個月後 Arora 給出了實驗上的證明,證明真的發生了!這也是《GAN 系列文 5》要說的。
Equilibrium
但講到現在我們都還沒回答「為什麼最後一定是 generator 會贏?」這個重要的問題。
Game theory
在回答這個問題之前,需要用到一點點賽局理論,並且要先好好定義什麼是『平衡點』 ( Equilibrium )。對於每個遊戲,都有一個 payoff function,在我們的討論中,這個其實就是我們 (1) 式中要去 min max 的那個函數。所謂的『平衡點』,其實就是:
當玩家 1 選定了一個他最好的策略,然後玩家 2 再根據玩家 1 的策略選擇對他自己最好的策略;反過來,當玩家 2 選定了一個他最好的策略,然後玩家 1 再根據玩家 2 的策略選擇對他自己最好的策略。如果兩種方式玩出來的解都一樣,那就說這個遊戲有『平衡點』。
在賽局理論中,一個 2-player game 「可能」會不存在這樣的『平衡點』。而很不幸的,我們原本 GAN 的架構就是依個 2-player game。而實際上,在 Goodfellow 在 2016 NIPS 會議上就有提到,現在實務上 GAN 在訓練的時候,常常會有「震盪」的情形。而這個震盪造成的最大的麻煩,就是所謂的『Mode collapse』,或有人稱『Helvetica scenario』,簡單來說就是 generator 可能會將很多不同的輸入, 


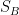
在『mixed strategies』中有平衡點的意思是:存在一個數字 
所有 a,面對 B 的策略的期望值都不大於
所有 b,面對 A 的策略的期望值都不小於
不過上面的平衡點是發生在 Generator 和 Discriminator 都有無限多個情況下。在實務上,只有「有限多個 generator 」和「有限多個 discriminator 」( 甚至只有一個 ),而且我們很貪心,希望 generator 總是贏。因此我們只能得到所謂的 ![[V-\epsilon, V+\epsilon]](https://s0.wp.com/latex.php?latex=%5BV-%5Cepsilon%2C+V%2B%5Cepsilon%5D&bg=ffffff&fg=000000&s=0&c=20201002)
這篇論文的最終目標是用一個稍微大一點點的 generator 去模擬「有限多個
這個有 『mixed strategies』的 generator ,和一個最佳解就只能是隨便亂猜的 discriminator 可以形成一個
如果只想知道文章開頭提問的答案,看到這裡就可以結束了 XD ,下面只是簡單提一下如何製造這個 generator 的概念。
如何製造一個 -approximate equilibrium 的情況?
無限多的 generator v.s. 一個 discriminator
如果有無限多的 generator 而且可以將它們混合,那很顯然的這個混合版的 generator 一定超強,因為機率上,『對於任何一個 distribution
有限多的 generator v.s. 一個 discriminator
如果 generator 跟 discriminator 的可調參數都只有 n 個。則從 

一個超強 generator v.s. 一個 discriminator
但是公然的用多個 generator 去打一個 discriminator 顯然太不公平了,所以只好想辦法做出單一一個 generator ,而這個超強 generator 其實就是要想辦法『模擬有限多的 generator 』。如果現在有 
這些問題筆者猜測其實很多人質疑過,但直到 2017 才由 Arora、Rong Ge 等人提出三篇論文,用嚴謹的數學證明、以及實驗驗證來給這些問題一些答案。而當然這方面的研究並不是到這裡就結束了,還有很多疑惑需要更多人幫忙解決,畢竟 GAN 這個模型發展到現在也才三年,還在一個不成熟的時期。

GAN系列文(4)–Generalization and Equilibrium in GANs 有 “ 2 則迴響 ”