本篇接續《Online learning — introduction》,我們給出一個 online learning 十分常見的架構,以及從它衍伸出來的 regret 的定義做更充分的討論。
Expert Advice
在 introduction 中有提到,面對 online learning 的問題,我們在乎的通常是 regret ,也就是跟「後見之明」比起來希望不要太差。但在 online learning 中,我們早已脫離了「有一個最好的 
專家意見 Expert advice
雖然在 online learning 一開始,玩家對問題一竅不通,但幸運的是現在玩家身邊有 K 個專家願意為他做預測,不過究竟哪個專家才是最厲害的也不知道。無論如何,現在的目標是玩家看能不能有一個策略,使得他最終的獲利﹝reward﹞跟最厲害的專家相去不遠。前句的『最終』,在 online learning ,大家約定成俗就是經過 
玩家身邊有 K 個專家:![[K]:=\{1,2,\cdots,K\}](https://s0.wp.com/latex.php?latex=%5BK%5D%3A%3D%5C%7B1%2C2%2C%5Ccdots%2CK%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![t\in [T]](https://s0.wp.com/latex.php?latex=t%5Cin+%5BT%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![x_t[i]](https://s0.wp.com/latex.php?latex=x_t%5Bi%5D&bg=ffffff&fg=000000&s=0&c=20201002)


![\ell_t\in [0,1]^K](https://s0.wp.com/latex.php?latex=%5Cell_t%5Cin+%5B0%2C1%5D%5EK&bg=ffffff&fg=000000&s=0&c=20201002)
![\ell_t[i]](https://s0.wp.com/latex.php?latex=%5Cell_t%5Bi%5D&bg=ffffff&fg=000000&s=0&c=20201002)


![\ell_t[I_t]](https://s0.wp.com/latex.php?latex=%5Cell_t%5BI_t%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\mbox{regret}:=\sum\limits_{t=1}^T \ell_t[I_t]-\min_i\ell_t[i] -- (1)](https://s0.wp.com/latex.php?latex=%5Cmbox%7Bregret%7D%3A%3D%5Csum%5Climits_%7Bt%3D1%7D%5ET+%5Cell_t%5BI_t%5D-%5Cmin_i%5Cell_t%5Bi%5D+--+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
玩家在做選擇的時候,只知道從 

這裡有一些東西需要補充。上面有講到獲利(reward),還有失誤(loss),在文獻中兩種都會出現,但這其實很容易處理,跟失誤相反,獲利是越高越好,因此 regret 就會訂成
![\mbox{regret}:=\sum\limits_{t=1}^T\max_i\ell_t[i]- \ell_t[I_t]](https://s0.wp.com/latex.php?latex=%5Cmbox%7Bregret%7D%3A%3D%5Csum%5Climits_%7Bt%3D1%7D%5ET%5Cmax_i%5Cell_t%5Bi%5D-+%5Cell_t%5BI_t%5D&bg=ffffff&fg=000000&s=0&c=20201002)
這樣寫也是因為 regret 約定成俗就是一個非負實數,不過用兩種方式得出來的 regret 是一樣的。通常通常,在大部分的情境看到的都是 loss,除了 stochastic setting,當初在發展這方面的研究時,用的就是獲利,因此現在很多時候還沿用此習慣。
第二,上面有兩個打()的部分,在很多變形的設定,這些並不一定會被特別寫出來。第一個()是因為有時候是不一定有這個東西,有時候是有沒有都無所謂。無所謂是因為玩家在做決定時,就只知道 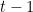
![\ell(t,k), \mbox{where } t\in [T], k\in [K]](https://s0.wp.com/latex.php?latex=%5Cell%28t%2Ck%29%2C+%5Cmbox%7Bwhere+%7D+t%5Cin+%5BT%5D%2C+k%5Cin+%5BK%5D&bg=ffffff&fg=000000&s=0&c=20201002)


Regret
regret 看似很單純,但其實也有值得著墨的地方。現在採用失誤(loss)的形式,並把 (1) 寫成
![\mbox{regret}:=\min_i\sum\limits_{t=1}^T (\ell_t[I_t]-\ell_t[i]) -- (2)](https://s0.wp.com/latex.php?latex=%5Cmbox%7Bregret%7D%3A%3D%5Cmin_i%5Csum%5Climits_%7Bt%3D1%7D%5ET+%28%5Cell_t%5BI_t%5D-%5Cell_t%5Bi%5D%29+--+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
(1) 跟 (2) 是一樣的,只是寫成 (2) 比較方便接下來的討論。通常玩家的策略會有隨機的因素在裡頭,而有時環境也有一些隨機性,因此我們不太會直接說 regret 是多少,而是會去問 expected regret bound 或是 high probability bound。現在說的 expected regret 其實是比較廣義的,就是要考慮所有 random bit 加權的情況,但它其實還可以再細分成兩種,分別對應到 adversarial setting 和 stochastic setting 常用的 regret。
在 adversarial setting 下常用 expected regret ,它定義成
![\mathbb{E}\left[Reg_T\right]:=\mathbb{E}\left[\min_i\sum\limits_{t=1}^T (\ell_t[I_t]-\ell_t[i])\right]=\mathbb{E}\left[\sum\limits_{t=1}^T\left(\ell_t[I_t]-\ell_t[i^*_T]\right)\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BReg_T%5Cright%5D%3A%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Cmin_i%5Csum%5Climits_%7Bt%3D1%7D%5ET+%28%5Cell_t%5BI_t%5D-%5Cell_t%5Bi%5D%29%5Cright%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Csum%5Climits_%7Bt%3D1%7D%5ET%5Cleft%28%5Cell_t%5BI_t%5D-%5Cell_t%5Bi%5E%2A_T%5D%5Cright%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
其中 


![\overline{Reg_T}:=\min_i\mathbb{E}\left[\sum\limits_{t=1}^T\left(\ell_t[I_t]-\ell_t[i]\right)\right]=\mathbb{E}\left[\sum\limits_{t=1}^T\left(\ell_t[I_t]-\ell_t[i^*]\right)\right]](https://s0.wp.com/latex.php?latex=%5Coverline%7BReg_T%7D%3A%3D%5Cmin_i%5Cmathbb%7BE%7D%5Cleft%5B%5Csum%5Climits_%7Bt%3D1%7D%5ET%5Cleft%28%5Cell_t%5BI_t%5D-%5Cell_t%5Bi%5D%5Cright%29%5Cright%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Csum%5Climits_%7Bt%3D1%7D%5ET%5Cleft%28%5Cell_t%5BI_t%5D-%5Cell_t%5Bi%5E%2A%5D%5Cright%29%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
其中 
![\overline{Reg_T}\leq \mathbb{E}\left[Reg_T\right]](https://s0.wp.com/latex.php?latex=%5Coverline%7BReg_T%7D%5Cleq+%5Cmathbb%7BE%7D%5Cleft%5BReg_T%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
大家常常又會把 pseudo regret 繼續改寫成
![=\sum\limits_{t=1}^T\mathbb{E}\left[\mu_{I_t}-\mu^*\right]=\sum\limits_{t=1}^T\sum\limits_i\left[\mu_i-\mu^*\right]\mathbb{P}\left[I_t=i\right]=\sum\limits_{i}\left[\mu_i-\mu^*\right]\mathbb{E}\left[N_T(i)\right]](https://s0.wp.com/latex.php?latex=%3D%5Csum%5Climits_%7Bt%3D1%7D%5ET%5Cmathbb%7BE%7D%5Cleft%5B%5Cmu_%7BI_t%7D-%5Cmu%5E%2A%5Cright%5D%3D%5Csum%5Climits_%7Bt%3D1%7D%5ET%5Csum%5Climits_i%5Cleft%5B%5Cmu_i-%5Cmu%5E%2A%5Cright%5D%5Cmathbb%7BP%7D%5Cleft%5BI_t%3Di%5Cright%5D%3D%5Csum%5Climits_%7Bi%7D%5Cleft%5B%5Cmu_i-%5Cmu%5E%2A%5Cright%5D%5Cmathbb%7BE%7D%5Cleft%5BN_T%28i%29%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
其中 
![\left[\mu_i-\mu^*\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cmu_i-%5Cmu%5E%2A%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
如果希望 pseudo regret 很低,那意味著那些『不好的』專家不能被選擇太多次,而要盡量選擇那個最好的專家,因為他的 mean 正是 
Reference
- Bubeck 跟 Cesa-Bianchi 寫的 “Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems",在 Introduction 中寫的蠻清楚的。
- Shai Shalev-Shwartz 的 “Online Learning and Online Convex Optimization" .
- V.Vovk 的 “A game of prediction with expert advice".
