這篇文章主要根據實驗室同事王昱舒(台大資工系 B04 級)於2018/08/31 在中研院資訊所的報告紀錄而成。報告內容是 2018 ICML 其中一篇獲得 best paper award 的論文:Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples。以下會有關於 adversarial examples 的基本介紹,以及提到 adversarial examples 如何影響機器學習的安全性。
Introduction
在機器學習目前普遍被認為做的很好,甚至比人類表現得好的問題中,其中一個就是分類問題。分類是很多更進階問題的基礎,例如:如果機器學會了分類,那麼將很有可能可以代替人類做很多諸如此類的判斷性的工作;又或者是,我們希望可以創造自動車,那麼其中一件重要的事情,就是要教會機器如何判斷交通號誌和不一樣的交通狀況以做出適當的反應。


像是第二列這種,被修改了一點點就使得機器嚴重出錯的圖,就被稱為對抗例(Adversarial examples),這種對抗例,讓機器學習應用於現實生活中急需『準確性』的工作造成十分大的威脅,像是「自動車駕駛」、像是「臉部辨識安全系統」等等。
Why are there adversarial samples?
那為什麼會有這些 adversarial examples 呢?一個可以想見得的原因是:資料本身有其『真正的邊界』,也就是下圖中的虛線,與我們的模型看到訓練資料(下圖淺色的點)學到的邊界(實線)存在著差異。一旦有了差異,那麼就會存在 adversarial examples,例如下圖的藍色圈圈,以及紅色叉叉。以紅、藍圈圈舉例說明:紅色圈圈不管是對虛線還是實線來說,他都是同一類;但是對於非常接近的另一個點(藍色圈圈)來說,他在虛線的右邊、卻在實線的左邊,因此他就是這個模型的 adversarial example 。

Adversary’s knowledge

- 黑盒子(Black-box):攻擊者知道的訊息最少。對於他來說,我們就像是一個黑盒子,他看不到我們模型裡面的結構,只能觀察到我們的輸入、輸出資料。也就是說,只知道對於某一個輸入,模型會給出的答案,而輸入可以是 testing data、或甚至是 adversary 另外製造出的 data(但是他不知道 training data),總之他可以任意觀察我們對任何一筆資料的答案,但除此之外什麼都不知道。
- 白盒子(White-box):攻擊者知道的訊息最多,幾乎是把我們摸透的地步。不僅僅是模型對資料的答案,他還知道模型的結構、甚至是參數,因此攻擊者可以自己製造一模一樣的模型來做測試。也就是說,如果他在自己 local 端發現
是 adversarial example ,那對於我們真正的模型,
- 灰盒子(Gray-box):攻擊者擁有的資訊量比黑盒子多、比白盒子少的,都統稱為灰盒子。
大部分宣稱有『防禦能力』的模型,都希望能夠抵擋白盒子的攻擊,而本篇文章也是以討論白盒子攻擊為主。
Attack methods
Adversarial examples 定義
攻擊者的目標,就是要找到 adversarial example ,使得機器發生要命的失誤,但並不是所有機器回答錯誤的資料都叫做 adversarial example ,他有一些更嚴格的要求:『adversarial examples 是那些與被分類正確的資料很相像,但卻被分類錯誤的資料。』為什麼要這樣訂呢?一個最簡單可想見得的理由是因為它讓人『防不勝防』!一個只是明顯錯誤的資料,經過了更久之後的學習,總有一天會學好。但是那些存在在 decision boundary 、距離 training data 只有一步之差的資料,誰也不會想到他竟然被分錯了。
Attacker 尋找 Adversarial examples
基於這種定義,我們其實很容易可以發現攻擊者要怎麼樣尋找 adversarial example 比較合理和快速:
我們稱 


這個問題就變成了一個最佳化問題。但這個最佳化的解不是很好找,因此也可以換成另一個較常用,而且意思差不了太多的目標函數:

現在問題變成是希望找到某個錯誤的點 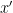
Defend methods
面對來勢洶洶的攻擊者,我們該怎麼防備才好呢?自古以來防衛工作幾乎總是較難,只要系統還沒做到滴水不漏,就還是可能被攻擊,而且相對地防衛者處的位置比較被動。總的來說,防衛者可能有兩種避免被攻擊的方向:1. 改善模型的邊界使得它跟真正的邊界更接近 2. 讓攻擊者很難找到 adversarial examples。
第一個方法,除非增加更多的訓練資料,否則幾乎可以說是不可能辦到;而第二種方法還有一些機會。近年來許多的論文都宣稱可以對抗白盒子攻擊,甚至其中一個 ML 會議 ICLR 在 2018 年就收了 9 篇不同的論文,可見研究者對於找尋方法來抵抗攻擊展現了極大的興趣。但是很不幸的,本篇文章開頭提到的這篇 best paper ,『Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples 』卻發現大部分的抵抗都屬於某一種特定的類型,而他們針對這種類型的抵抗,成功的設計出有效的攻擊方法。
Obfuscated Gradient
這篇論文指出,其中有 7 篇,無論是刻意或是不自覺的,使用的抵抗方法都屬於 Obfuscated Gradient,也就是對模型的 gradient 動手腳,像是讓函數變得不可微分等等。其實這個方法想起來也算合理,因為就像上一段提到的,攻擊者找 adversarial example 的最佳化問題,幾乎都是用 SGD 解的,那如果我們對 gradient 動手腳,便有可能成功使許多攻擊變得無效!
但作者們將 Obfuscated Gradient 主要分成 3 大類,不僅針對每一類設計相應有效的攻擊方式,而且還提出可以檢驗這個模型是不是有可能屬於 Obfuscated Gradient 的方法。這一方面對於攻擊者來說是利多,因為如果發現這個模型可能符合這種特徵,那麼或許使用他們的方法就能有效攻擊,但相對的也提供給之後研究防禦方法的研究者一種指引,避免設計出來的防禦方式又陷入了差不多的種類。
現在我們先來介紹三種 Obfuscated Gradient :
- Shattered Gradient:Shattered Gradient 是使得函數不可微分、或是讓微分不是往解的方向走。無論是哪一種,都會讓攻擊者沒辦法順利利用 gradient descent 找到 adversarial examples。
- Stochastic Gradient:讓 network 帶有隨機性。這可以透過讓 network 本身就是一個隨機模型(randomized classifier),或者是讓 input data 透過另一個 random function
變成隨機資料。這些都會使得攻擊者沒辦法隨機根據一筆資料,就找到函數真正的 gradient 方向。
- Exploding / Vanishing gradient:設計超複雜的 neural network ,例如合併非常多個 network 組成一個,使得計算 back propagation 十分費工夫。
作者並提出了一些經驗上的檢驗方法。只要符合以下幾種的任一種,這個模型就很可能是利用 Obfuscated Gradient :
- 一次性攻擊(one-step attack)表現得比用迭代的方法找攻擊點(iterative attack)更有效
- 隨機找攻擊點反而比使用 gradient descent 更容易找到 adversarial example
- Black-box attack 表現得比 white-box attack 好
其實這幾點都是在講差不多的事情,也就是說,當攻擊者知道模型的結構、並想利用模型的結構解最佳化問題找解的時候,因為一步一步按順序找解的過程會使用到 gradient ,但是很不幸的 obfuscated gradient 的防禦破壞掉 gradient 的訊息,因此攻擊者表現的反而比不知道結構時還差。
Attack Techniques for Obfuscated Gradients
終於進入本篇論文最後的部分了,也就是作者到底用了什麼方法分別攻擊上述三種 obfuscated gradients。
Shattered Gradient — BPDA
Backward Pass Differentiable Approximation (BPDA) 的想法其實很單純,就是攻擊者可以將原本不可微分的模型(


整個訓練過程其實包含了 forward pass 跟 backward pass,而 forward pass 只是要算出值,不需要使用到微分,因此 forward 為了維持正確性、不要讓『近似』這個步驟造成額外無謂的損失,所以用
Stochastic Gradient — EOT
Expectation over Transformation (EOT) ,顧名思義就是用期望值去對付含了隨機性的 neural network。Stochastic gradient 給攻擊者最大的困擾,就是沒辦法直接使用 stochastic gradient descent 去找到真正的 gradient 方向,但這也意味著我們只要能夠想辦法找到那個方向就行了。因此,針對那些利用 random function 
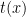

又由於 

Exploding / Vanishing Gradient — Reparameterization
第三種,整個 network 被改的超大超複雜,但是沒關係,我們一樣可以利用像是 BPDA 的方法,用一個小一點,但是效果差不多的 network 去替代原本那個超複雜的就行了。作者們將它分作第三類,但筆者認為其實概念上跟 BPDA 是差不多的。
Experiments
作者將他們的攻擊方法,拿來做在 ICLR 2018 那 7 篇用到 obfuscated gradient 的防禦方法,成功的攻擊了其中 6 個,讓防禦方的正確率掉到不到 10 %,算是出奇的成功,除了其中一種方法,仍然保有 55 % 的正確率。

Discussion
adversarial example 當然不僅僅是存在於分類(classification)問題中,其他種類的問題也有相對應的 adversarial example ,他們都會對以機器學習為基礎的模型(machine learning-based model)造成安全性的威脅。
雖然其中有 7 篇都使用到了 obfuscated gradient 的概念,但其中一篇作者利用新的方法攻擊後,卻還有 55 % 正確率有點令人驚訝,我猜讀者們也有同樣的疑問,有機會的話筆者去好好研究一下那一篇再來跟大家分享。
筆者私自認為,要達到真正的 white-box robustness 其實是非常困難的,一方面只要面對 training data 沒有達到 100% 正確率,那就一定會存在 adversarial example ,但是實作上我們又不希望 training 時真的訓練到 100% ,因為那幾乎都 overfit 了,通常沒有好下場。在這兩者間如何取得平衡,或許是研究機器學習安全問題的研究者不得不面對的問題。
[ 參考資料 ]
- http://www.cleverhans.io (本網站為 Ian Goodfellow 和 Nicolas Papernot 所寫的關於『機器學習的安全問題』的網誌)
- https://secml.github.io/class1/ (本網站是今年 University of Virginia 開的一門新的課,看起來主要以討論論文為主,值得一看)
