經由上一篇<<PAC lernability>>的討論,我們還是沒有辦法說學習真的是可行的,為什麼?因為儘管在上一篇的最後已經把過於理想的Realizability assumption 去除了,但是仍舊有一個不太合理的假設我們還沒解決:我們能在訓練資料上表現地很完美,也就是
讓

經由上一篇<<PAC lernability>>的討論,我們還是沒有辦法說學習真的是可行的,為什麼?因為儘管在上一篇的最後已經把過於理想的Realizability assumption 去除了,但是仍舊有一個不太合理的假設我們還沒解決:我們能在訓練資料上表現地很完美,也就是
讓
從<<機器學習可行嗎(1)>>我們有概念:學習是希望從舊有的經驗中找尋規則,並在面對沒有看過的資料時也能成功預測。
現在問題來了,要怎麼能夠說這個模型「學得好」了呢?是要要求它「每次」都能「零錯誤率」?這樣似乎太嚴苛了。但是多少的錯誤率是可以接受的呢?又一定要每次都對嗎?還是大部分時候是對的就好?還有「尋找使得訓練錯誤率最低的函數」﹝ERM﹞這個方法什麼時候會是不錯的方法呢?
因此這次我們要討論的主題就是PAC learnability,幫助我們定量的描述什麼叫做「學得好」。
由<<初體驗–第一個演算法PLA>>我們發現,機器學習似乎是可以辦到的。
從這個新的單元<<機器學習可行嗎>>開始,我們將正式的來分析機器學習的條件有任何限制嗎?又或者是有沒有一個全知全能的演算法可以告訴我們所有問題的答案呢?不過首先我們要先來釐清一件小小的事情。
上一篇<<Problem Setup>>講了一些我們期待電腦能夠做到的目標,也做了一些基礎設定,但是我們還是不知道,究竟電腦能不能夠從『訓練資料』(training set)中學到一點什麼呢?也就是在『候選函數』(hypothesis set, 


在科技蓬勃發展的21世紀,電腦已經幾乎是生活中不可或缺的一部分了。而隨著電腦運算能力的突飛猛進,它已經能解決許多非常不可思議、甚至只靠人力沒有辦法解決的問題。最明顯的例子之一是,現今我們手機、電腦等等的電子產品,裡面往往都存有數十億顆電晶體。數十億顆電晶體應該如何排列、如何供電,已經不是我們靠著紙筆計算就能夠知道的了,因此我們需要撰寫程式,讓電腦用比人類更「快速」的速度計算這個問題,告訴我們答案。但是儘管電腦計算能力如此強大,在這個階段,它充其量就是個「計算機」,只能一步一步執行我們的指令。
而人類最自豪與其他生物不同的地方,大概在於覺得人類擁有更高的「思考」能力。但無奈人腦的計算速度再怎麼快也快不過電腦。因此我們開始思考,如果人類的思考能力和電腦的計算速度能夠結合,那啟不是太好了嗎?
機器學習,顧名思義就是希望機器,也就是我們的電腦,可以自己學習,讓它像是人類一般擁有思考能力,而不是只有一步一步遵循步驟。但機器真的能夠自己學習嗎?如果可以,那哪些問題是機器確實能夠學習的呢?為了討論、或是解答這樣的問題,我們需要指定一些共通的敘述方式,來描述一些特定的問題、或是特定的算法等等。
以下的代號和它所代表的意義將會持續出現在往後的討論當中。
: 輸入(input),
: 輸入空間(input space)
: 輸出(output),
: 輸出空間(output space)
: 目標函數(target function)
先來解釋何謂輸入空間、輸出空間以及目標函數。先舉兩個例子:
例一、
假設某一間銀行有提供貸款的服務,但也不是誰需要都能借。銀行希望可以由以前借款人的表現來評估借款給某些人對銀行是不是有利的。因此他開始想要分析這一些手上已經掌握的顧客資料:顧客年齡、目前財產、工作狀況、愈借款金額、還款期限等等等,而每一筆顧客資料後面都會加註:「借出」或是「拒絕」的最後決定。在這個例子當中,每一個顧客的顧客年齡、財產等等的狀態,就是我們的『輸入』(input),若有很多個顧客各自的資料,那他們就形成了一個『輸入空間』(input space);而最後的「借出」或是「拒絕」就是『輸出』(output),同樣的,若有很多不同的判斷結果,則所有可能結果就形成了『輸出空間』(output space)。
最後,何謂『目標函數』呢?函數指的是不同的
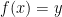
在這個例子當中值得注意的是,我們可以發現,輸入有可能有很多個值,也就是有很多個變數(形成一個向量空間 

例二、
若現在我們想要解決的是電影類型的問題,希望能夠透過一些資料判斷某一部電影是屬於喜劇片、愛情片、動作片、動畫等等,大於2種結果的分類問題,那我們的『輸出空間』就會大於兩種,而變成『多元分類問題』(multiclass classification) 。
現在,接續第一個例子的背景,有個職員已經工作了10年了,每天如此這般的問總裁,好歹也累積了一點經驗,就算他不知道總裁確切的心意,但也能從這些年來的判斷結果猜出一點端倪。假設他手上有n筆資料,他希望能夠從這n筆資料找出一點規則,也就是藉這n筆資料猜出總裁的心意
: 訓練資料(training examples)
在正式開始猜測目標函數之前,該職員心裡可能早就已經存在一些『候選函數』:
: 候選函數集(hypothesis set)
: 學習者,目標是從

: 學習者看了某些訓練資料
而選出的函數
不過這裡還有一個問題是,如果現在前線的職員被分成很多個固定的窗口,A職員負責高屏地區顧客,B職員負責雲嘉南地區,C職員負責中投竹苗,D職員負責大台北,而E職員負責花東。想當然爾,這幾個地區的顧客背景很可能有很大的差異,也就是他們會接收到的訓練資料的分佈情形不同,而只有總裁擁有全部的資料。職員接收到的資料分佈分別寫成

: 某筆訓練資料的分佈
到目前,我們已經將一些「學習」的問題做了一點介紹。那這跟我們有興趣的機器學習有什麼關係呢?假設現在,我們希望電腦替我們做那件職員做的事情,在這個資訊量爆炸的年代,我們很容易就能獲得很多很多訓練資料,但是卻不一定知道總裁心意。我們希望電腦跟該職員一樣,收到許多資料後,用它自己某一套方法,猜出總裁的心意。在這樣的狀況底下,我們就將
現在,我想我們已經擁有了一些基本概念以及共通的語言,在往後的文章中,我們將會利用這些表示方式來討論機器是否能夠學習,以及機器可以怎麼學習等等的問題。

