在很多時候我們都需要『距離』的概念,比如果我問我們兩個離的很近嗎?你可能回答:『大概距離 100 公尺吧!』而這樣的度量就會在我們的心中成形,例如我大概可以估計我們大概在距離跑步 20 秒的距離吧。那在機器學習問題中,『距離』也是個不可或缺的度量,例如我手上有 A、B、C 三張長寬是 100 * 100 個小格子組成的圖片好了,那我問:『是圖 A 跟圖 B 比較像?還是圖 A 跟圖 C 比較像?』這時該怎麼辦?
我們的電腦顯示出來的顏色基本上是由三種原色組成的,三種顏色有各自的比例,那這時你可能就會想到,我把兩張圖片疊在一起,然後計算相對應的小格子的三種顏色的比例距離,像是A、B兩圖的比例分別是 A (24, 24, 52),B (30, 40, 30),那我們就可以計算在這樣的三維空間他們的歐式距離 
到這裡應該都非常直觀,但是接下來,如果我們想知道兩個『機率分佈』(Probability distribution) 的距離呢?像是我們要怎麼衡量下圖的兩個機率分佈?這可能就是件令人頭痛的事情。因此這篇文章主要就是介紹幾個在機器學習中常被使用的衡量機率分布的方法。這篇文章不會太深入地談論他們,大概就是到足以知道後面的文章在說什麼也就足夠了。如果有興趣研讀更多可以去尋找專業的教科書或是讀讀 [reference] 中的幾篇文章。

0. Shannon Entropy
在這之前先來談談「資訊量」好了。訊息理論(Information theory)是1948年由 Shannon 提出,主要是希望能夠衡量當我們聽到、或是說觀測到一個事件時,那個事件帶給我們的資訊量有多少?他用很美妙的數學將這個聽起來很概略的概念量化,並且讓我們能夠『比較』資訊量,而這件事情在通訊上、密碼學上都是很重要的。
先舉個例子暖身。如果有天你聽到一句話:「今天太陽從東邊升起欸!」你可能第一個反應是:「……WTF……」嗯,因為這件事對大部分的人來說太顯然了(發生機率是1),我們覺得聽到這句話沒有得到任何資訊量,如果每則資訊都值一筆錢,這筆可能一毛錢都拿不到。如果現在是總統大選開票的時刻,現在只有兩個候選人,而選前的民調表現出來是五五波,兩人當選機率都是 1/2 ,哇這下可緊張了!如果這時候科技還沒那麼發達,開票結果沒有那麼『即時』,大概會誤差個一個小時,那當有人宣稱:「我知道誰當選了!想知道的付10萬我就跟他說!這則訊息值很多錢,因為答對的機率只有一半,這則訊息帶來的資訊量太大了,身為一個牆頭草,這攸關接下來四年他要往左邊還是右邊倒啊(?)因此看到這裡可能有個感覺:當情況越明確,也就是事件發生的機率越不平均,搞清楚這件事情需要的資訊量(金錢)就只要很少,而當情況越不明確,也就是每件事發生的機率都差不多,把這件事搞清楚所需要的資訊量(金錢)就會比較多。而在訊息理論(Information theory)中,資訊量將會是機率的函數。
Shannon 用了一條公式表示了這件事:

X 表示一個隨機變數,而 
- ( A , B ) = ( 1 , 0 )
- ( A , B ) = ( 0.5, 0.5 )
則根據上述公式,
,也就是這個硬幣沒有任何的「不確定性」在,要猜測他的結果並不需要任何資訊量,因為我們早就知道了。
,可以發現這樣的公正骰子每一次投擲帶的資訊量是很大的,因為想要知道投擲一次〈一單位〉的結果,就必須觀測一單位的訊息。
而事實上如果我們連續的改變A、B事件的機率,則可以畫出下面這張圖。圖中的 (X=1) 就是指發生A事件,而縱軸就是 Shannon entropy 。可以發現當 A 出現的機率越接近 0 或 1 〈越確定〉,Shannon entropy 就越低,越容易猜到他。

最後,上面提到的『訊息量』如果用專業一點的方式講,就是 “bit" ,也就是電腦科學中常用的『位元』。而如果現在我們的問題不只是想要傳遞『擲骰子的結果』,而是更複雜的資訊,例如傳送一串字元好了,這整個字元集為 X ,而裡面每個字元 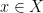
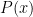
1. KL 散度(KL divergence)
Kullback–Leibler divergence ( KL 散度 ) 或又叫 relative entropy (相對熵),這是我們介紹的第一種衡量兩個機率分佈P、Q『距離』的方法,而他表示的是:「若用基於 Q 這個機率分佈編碼的語言,要傳送來自於P這個機率分佈的資料 x ,需要比直接基於 P 編碼的語言傳遞這個資料 x 多花的代價(位元)。」這句話乍看之下不知道到底想表示什麼,但或許直觀上可以理解成一個我們常見的情境:「用中文(Q)表達某個本來就只有台語(P)有的詞(x),比直接用台語講那個詞要多花多少口水?」這樣想或許就容易理解一點了。
有了直觀的理解之後我們來看正式的定義。KL divergence 定義成:
![D_{KL}(P||Q)=E_{x\sim P}[log_2\frac{P(x)}{Q(x)}]](https://s0.wp.com/latex.php?latex=D_%7BKL%7D%28P%7C%7CQ%29%3DE_%7Bx%5Csim+P%7D%5Blog_2%5Cfrac%7BP%28x%29%7D%7BQ%28x%29%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)


這個不等式可以簡單用 Jensen’s inequality 證明,或是隨便翻一本機率的書都會有,在這裡就不多提。這裡只要強調,這個性質大概是 KL divergence 唯一一個滿足『距離』這個特性的,也就是非負,且事實上它的值是有可能到無限大的。那什麼時候等號會成立呢?若且為若
幾乎處處成立。或是有學過機率的,可以用機率的語言理解:『P and Q are equal almost surely.』
- KL divergence 不對稱,也就是
,這個在上面提過,可以直接看定義就能驗證。

但看到這裡我們可能還很困惑,那這個 KL divergence ,跟剛開始提的:「用中文(Q)表達某個本來就只有台語(P)有的詞(x),比直接用台語講那個詞要多花多少口水?」有什麼關係?讓我們把 KL divergence 的定義稍微做的變形就能看出來。

可以發現第一項其實就是負的 H(P),而如果我們再定義 P 跟 Q 的『交叉墒』( cross entropy ) 為:

則 
把原本的定義改寫成 (1) 式有什麼意義?不就展開嘛?有的!如果我說我用中文 ( P ) 說某個原本就是中文 ( P ) 的詞 X 需要使用 30 個位元,而用英文 ( Q ) 說必須使用 55 個位元,則用英文 ( Q ) 說比用中文 ( P ) 必須多花 25 位元的代價。
再回想上面提到
2. JS 散度
Jensen-Shannon divergence ( JS divergence ) 是根據 KL divergence 而衍生出來的另一個定義,但是這個定義改掉了 KL divergence 最大的缺點:不對稱。讓我們來看看 JS divergence 的定義便能明白為什麼他能夠是個對稱的衡量。


這樣就很明白了,JS divergence 計算的是『 從分佈 Q 到 M 的 KL 散度 』加上『 從分佈 P 到 M 的 KL 散度 』,且『M 是 PQ 的平均』。
JS divergence 的值域會有一個範圍,至於範圍是什麼端看 KL divergence 的 log 值是以什麼為底數。我們將會使用的兩個如下:
- 當 KL divergence 的 log 是以 2 為底,則
- 當 KL divergence 的 log 是以 e 為底,則


這個讀者也能輕易驗證。要特別注意的是當 P 跟 Q 越接近時,JSD 越小,這件事在往後的文章中非常重要。
3. Wasserstein 距離
Wasserstein distance (Wasserstein distance ) ,又或是 Earth-Mover distance ( EM distance ),我們直接看定義:


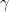



直觀上理解『 Wasserstein 距離』的意義的話:
P 跟 Q 的分布如果越接近,則對某條『路徑』,
但為什麼要訂這樣的距離呢?它比起前兩者有什麼好處嗎?答案是,有的!Wasserstein 距離比起 KL divergence 跟 JS divergence 更好的地方在:它能更好的反應兩個分佈的距離,在某一些特別的情況下。這裡容我賣個關子,關於這個的說明我將會在往後的文章中提及,因為這牽涉了為什麼我要寫這一系列的文章XD

GAN系列文(1)–distance of distribution 有 “ 2 則迴響 ”