這篇文章基本上延續了《GAN系列文(2)–Generative Adversarial Nets》對於 GAN 這個模型的研究。先稍微對 GAN 的幾個重要結論做個小複習:
GAN 的目標函數是:
![\min_G\max_D \mathbb{E}_{x\sim P_{data}}[log(D(x))]+\mathbb{E}_{x\sim P_G}[log(1-D(x))]](https://s0.wp.com/latex.php?latex=%5Cmin_G%5Cmax_D+%5Cmathbb%7BE%7D_%7Bx%5Csim+P_%7Bdata%7D%7D%5Blog%28D%28x%29%29%5D%2B%5Cmathbb%7BE%7D_%7Bx%5Csim+P_G%7D%5Blog%281-D%28x%29%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
而最佳的 discriminator 是:

當手上握有那麼好的 discriminator 時,Generator 的目標就是去最小化 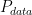


以及 GAN 的演算法:

本篇的主軸會放在回答那一篇文章最後提問的, GAN 在理論上似乎可行,但在實務上卻有很多困難:
- 訓練困難、不穩定。也就是 discriminator 跟 generator 學習的速度如果不好好控制,就會失控。〈Train 不起來〉
- Discriminator 和 Generator 的 loss 沒有辦法充分顯示訓練到底進行得如何了。
- Generator 產生的樣本雖然真實,但缺乏多樣性,也就是當生成很多很多圖片後,會發現有某一些是非常像。
 個 sample 構成的 distribution,就足以騙過 discriminator。意思是,當 discriminator 的能力受到限制時,其實也沒有辦法督促 generator 學到更多的東西,造成產出來的圖片歧異度 ( diversity ) 不夠。但光是理論的猜測是不夠的,因此這篇文章是 Arora 和 Yi Zhang 在 2017 年 7 月提出的實驗證明。
個 sample 構成的 distribution,就足以騙過 discriminator。意思是,當 discriminator 的能力受到限制時,其實也沒有辦法督促 generator 學到更多的東西,造成產出來的圖片歧異度 ( diversity ) 不夠。但光是理論的猜測是不夠的,因此這篇文章是 Arora 和 Yi Zhang 在 2017 年 7 月提出的實驗證明。 那麼好的 discriminator 了。)
那麼好的 discriminator 了。) 嗎?
嗎?